Populating Timestream With Scraped Predictit Market Ticks 1
Posted on Wed 04 October 2023 in Election Modeling
Amazon Timestream is a fully managed time series database. It's a relatively new offering to the AWS serverless portfolio. Main Timestream use case is to store IoT device-generated time series data, but our goal is to eventually build a notification and monitoring system based on prediction market tick data that we’re going to store in Timestream. First we need to capture our data, and we’ll be using Scrapy, an application framework for crawling websites, to scrape market data from predictit.com, and store the market tick data in AWS Timestream. This will be initial exploratory working session. In the next section, we'll implement a full parse and store workflow on a schedule to capture real-time time-series market data.
Architecture
The python code to capture election night data will be hosted on an AWS serverless lambda function. An evenBridge trigger will execute the code every minute, and each election capture will be saved into on an s3 bucket.
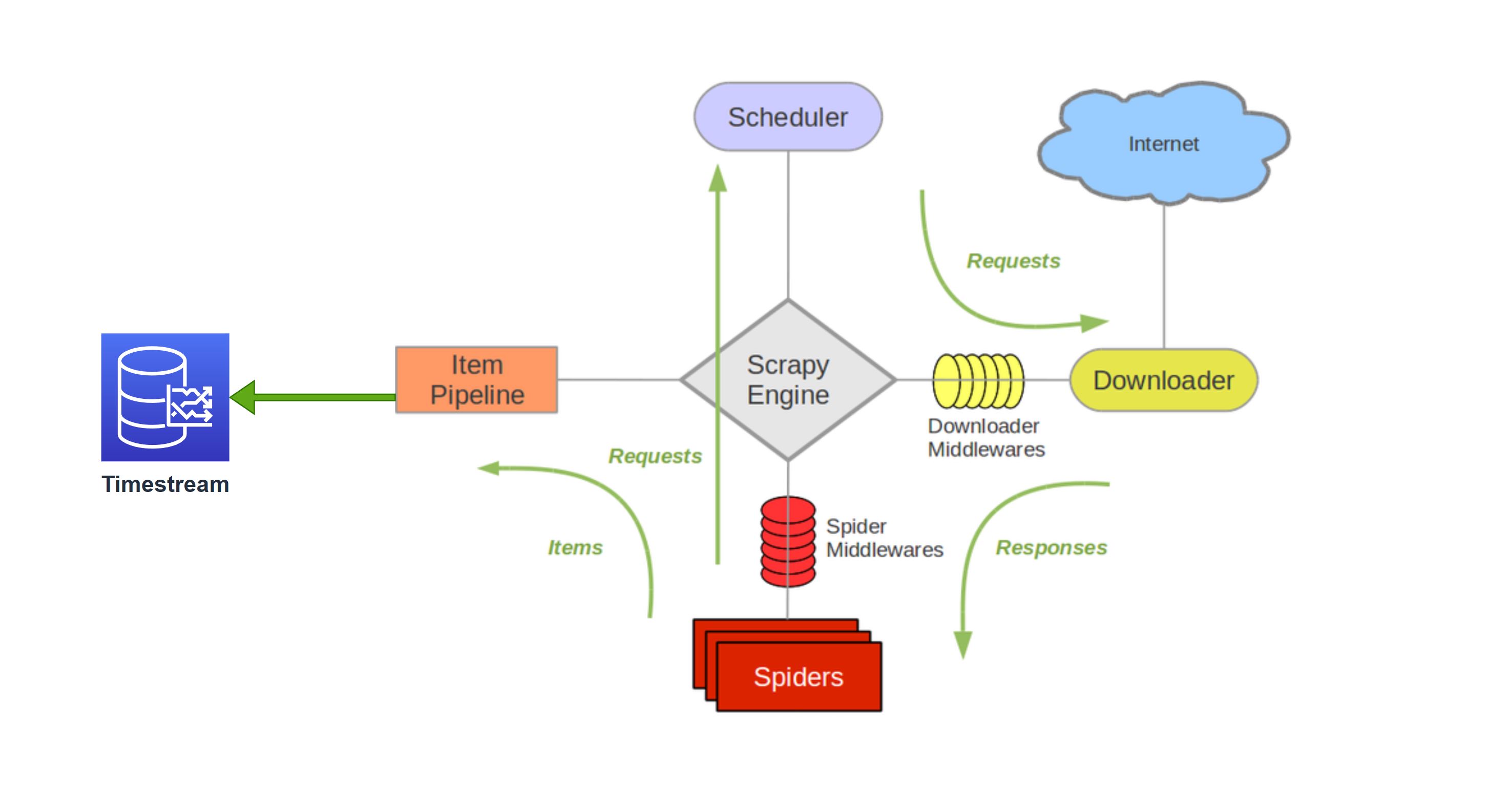
Scrapy will be doing heavy lifting with low level networking, scheduling, and downloading functionality. We'll implement two main parts of the scraping interface: * Spider – This is the entry point for our requests. This is where We specify the initial URL to crawl, after which we parse the response or scheduling subsequent requests in our scraping workflow. * Item Pipeline – Once extracted by the spider, the item is processed in the Item Pipeline. In our case, this is where we’re writing our scraped predict market data to Timestream
Before we implement any code, we need to create our Timestream database
Timestream
Before we implement code to scrape predictit markets, we need to create our Timestream database. Let's take a look at the data we're parsing to get an idea our schema.
Schema
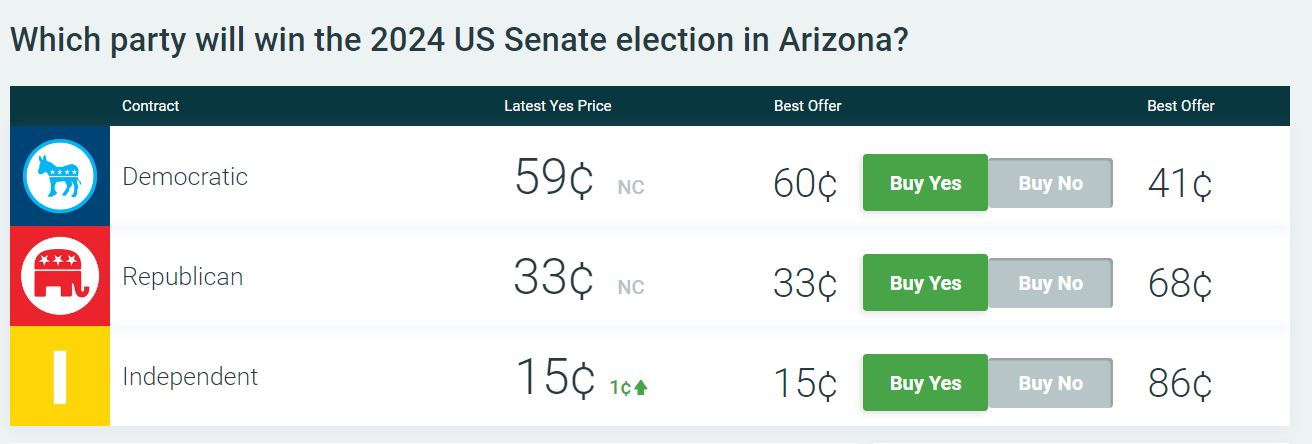
Predictit consists of markets at the top level, with contracts within each market. Each market is indexed by a market ID, and each contract is associated with a contract ID. In the above example:
| Market Name | Market ID | Contract Names | Contract IDs |
|---|---|---|---|
| "Which party will win the 2024 US Senate election in Arizona?" | 8070 | "Democratic" "Republican" "Independent" |
31257 31256 31258 |
Dimension represents the metadata attributes of the time series. The above values will comprise our Timestream dimensions.
Based on the Market ID, the Predictit API returns the below contract level data.
<xs:schema attributeFormDefault="unqualified" elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="ArrayOfContractListResourceModel">
<xs:complexType>
<xs:sequence>
<xs:element name="ContractListResourceModel" maxOccurs="unbounded" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:element type="xs:short" name="ContractId"/>
<xs:element type="xs:string" name="ContractName"/>
<xs:element type="xs:short" name="MarketId"/>
<xs:element type="xs:string" name="MarketName"/>
<xs:element type="xs:string" name="ContractImageUrl"/>
<xs:element type="xs:string" name="ContractImageSmallUrl"/>
<xs:element type="xs:string" name="IsActive"/>
<xs:element type="xs:string" name="IsOpen"/>
<xs:element type="xs:float" name="LastTradePrice"/>
<xs:element type="xs:float" name="LastClosePrice"/>
<xs:element type="xs:float" name="BestYesPrice"/>
<xs:element type="xs:short" name="BestYesQuantity"/>
<xs:element type="xs:string" name="BestNoPrice"/>
<xs:element type="xs:short" name="BestNoQuantity"/>
<xs:element type="xs:byte" name="UserPrediction"/>
<xs:element type="xs:byte" name="UserQuantity"/>
<xs:element type="xs:byte" name="UserOpenOrdersBuyQuantity"/>
<xs:element type="xs:byte" name="UserOpenOrdersSellQuantity"/>
<xs:element type="xs:byte" name="UserAveragePricePerShare"/>
<xs:element type="xs:string" name="IsTradingSuspended"/>
<xs:element type="xs:dateTime" name="DateOpened"/>
<xs:element type="xs:string" name="HiddenByDefault"/>
<xs:element type="xs:byte" name="DisplayOrder"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Measure is the actual value being measured by the record of the time series.
From the above, the measures we're going to store are:
- BestNoPrice
- BestYesQuantity
- BestYesPrice
- BestNoQuantity
- LastTradePrice
- LastClosePrice
Below is the final schema of our Timestream table.
| Column | Type | Timestream attribute type |
|---|---|---|
| Contract_ID | varchar | DIMENSION |
| Market_Name | varchar | DIMENSION |
| Market_ID | varchar | DIMENSION |
| Contract_Name | varchar | DIMENSION |
| measure_name | varchar | MEASURE_NAME |
| BestNoPrice | double | MULTI |
| BestYesQuantity | bigint | MULTI |
| BestYesPrice | double | MULTI |
| BestNoQuantity | bigint | MULTI |
| LastTradePrice | double | MULTI |
| LastClosePrice | double | MULTI |
| time | timestamp | TIMESTAMP |
The only other column, besides the Measure and the Dimension, is the TIMESTAMP.
Database
First we'll create our database
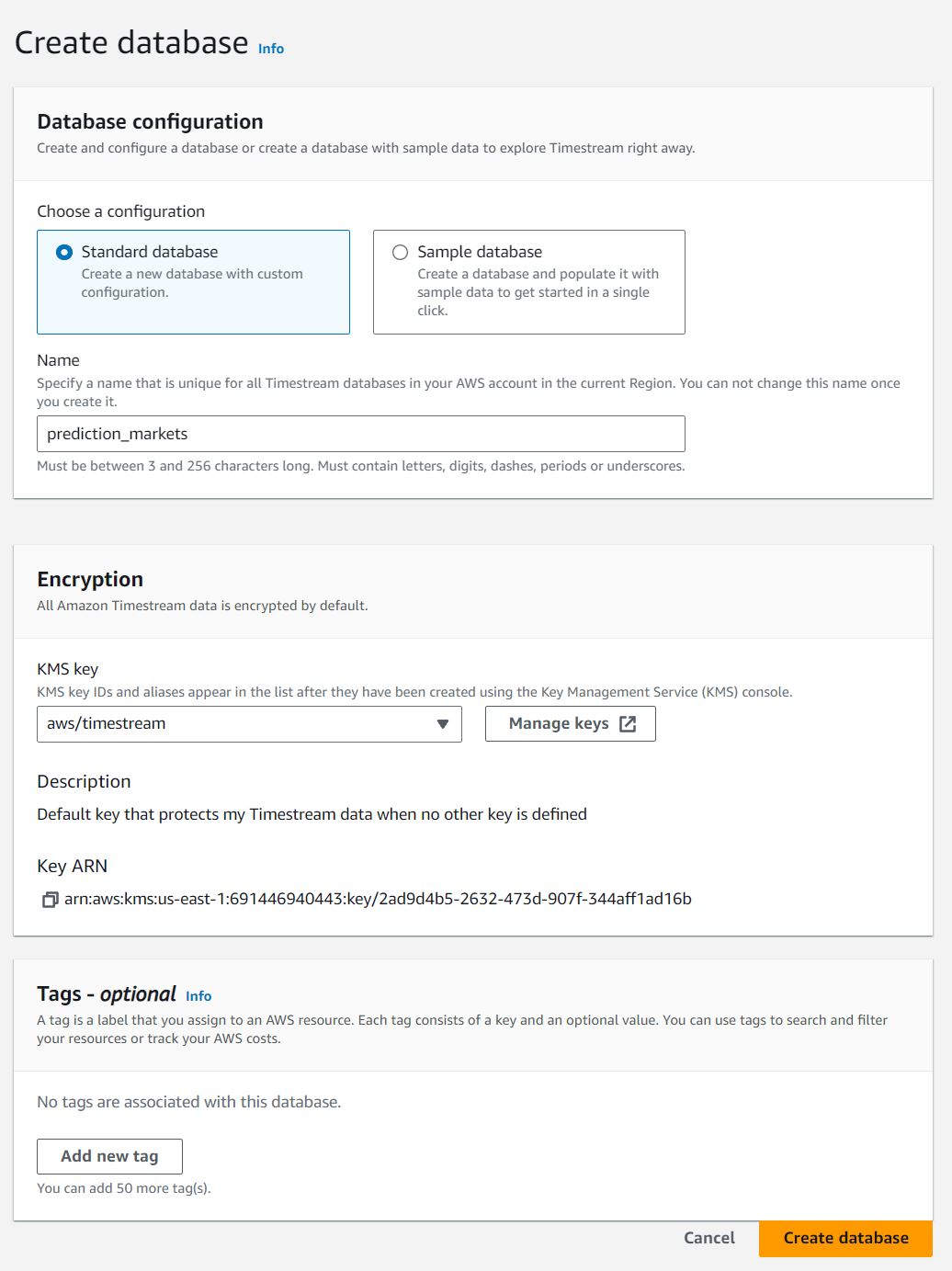
We'll name our database prediction_markets, and keep all other setting default.
Table
We'll call our table predictit
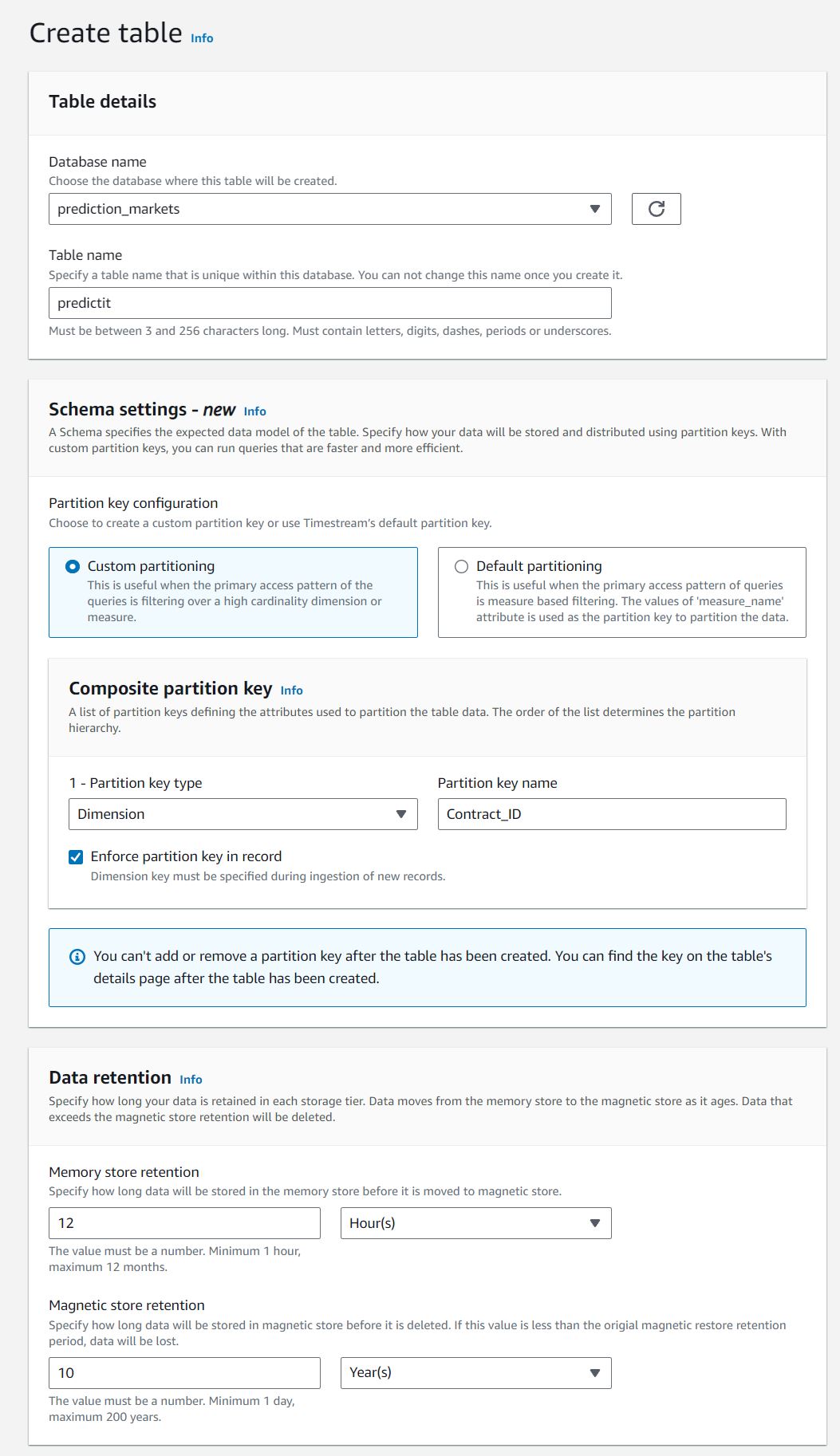
Timestream allows only one partition-key to be chosen on a table, and our main use-case will query based on Contract_ID, which will be our partition key, and keep all other setting default.
Scrapy
Now that we have our Timestream database created, we can implement our predictit scraping framework. Full code can be found here The entry point for scrapy is the spider class.
Spider
Spiders are classes where we define the custom behaviour for crawling and parsing pages for a particular site. for Predictit, we have two main pages to crawl
https://www.predictit.org/api/marketdata/all/- Data for all markets on the sitehttps://www.predictit.org/api/marketdata/markets/[Market_ID]- Data for a specific market indexed by Market_ID
We first get a list of all markets from api/marketdata/all/, we then get detailed contract data for each specific market returned from api/marketdata/markets/[Market_ID].
Below is our entry point for our spider class
class MarketSpider(scrapy.Spider):
name = "markets"
def start_requests(self):
#crawl main list of markets from marketdata/all to get list of markets
query = {}
base_url='https://www.predictit.org/'
path='api/marketdata/all'
urls = [
build_url(base_url,path,query),
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
The first requests to perform are obtained by calling the start_requests() method which generates Request for the URLs specified in urls and the parse method as callback function for the Requests.
def parse(self, response):
time = datetime.utcnow().isoformat()
#once list of markets is obtained from api/marketdata/all/
#crawl contract data for each individual market through api/Market/
base_url = 'https://www.predictit.org/'
base_path = 'api/Market/'
query = {}
for market in response.css('MarketData'):
loader = ItemLoader(item=MarketsItem(), selector=market)
loader.add_css('ID', 'ID::text')
loader.add_css('Name', 'Name::text')
loader.add_css('URL', 'URL::text')
loader.add_value('Time', time)
maket_id = market.css('ID::text').get()
self.log(f'market_id:{maket_id}')
if maket_id in MARKET_WATCHLIST:
#we only crawl market data from api/marketdata/all/ZA if it's in our list
path = base_path + maket_id + '/Contracts'
url = build_url(base_url, path, query)
self.log(f'url: {url}')
yield scrapy.Request(url=url, callback=self.parse_contracts,meta={'loader':loader})
else:
#otherwise, we take contract data from api/Market/
self.log(f'parse: MarketContracts')
item = MarketContractsItem
loader.add_value('Contracts', self.get_contracts(market,item))
yield loader.load_item()
In the parse callback function we get a list of market IDs, and we perform one of two parsing tasks:
1. Parse basic contract data for each individual market returned from api/marketdata/all/
2. Crawl and parse more detailed contract data for each individual market through api/marketdata/markets/[Market_ID] based on our specified list in MARKET_WATCHLIST.
Pipeline
After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially. In Our pipeline class, MarketsPipeline, the process_item method is called for every item pipeline component.
class MarketsPipeline:
# default constructor
def __init__(self):
self.write_api = None
self.client = None
def open_spider(self, spider):
_logging.info('create influxdb connections...')
try:
self.client = boto3.client('timestream-write')
except Exception as e:
_logging.error('connection error: %s', traceback.format_exc())
@staticmethod
def _current_milli_time():
return str(int(round(time.time() * 1000)))
def process_item(self, item, spider):
_logging.info("Item: "+str(item))
measurements = []
def def_value():
return None
def prepare_common_attributes(Market_ID, Market_Name,Contract_ID,Contract_Name):
common_attributes = {
'Dimensions': [
{'Name': 'Market_Name', 'Value': Market_Name},
{'Name': 'Market_ID', 'Value': Market_ID},
{'Name': 'Contract_ID', 'Value': Contract_ID},
{'Name': 'Contract_Name', 'Value': Contract_Name}
],
'MeasureName': 'market_tick',
'MeasureValueType': 'MULTI'
}
return common_attributes
def prepare_record(current_time):
record = {
'Time': str(current_time),
'MeasureValues': []
}
return record
def prepare_measure(measure_name, measure_value, measure_type):
measure = {
'Name': measure_name,
'Value': str(measure_value),
'Type': measure_type
}
return measure
time = datetime.utcnow().isoformat()
Inside process_item, we first implement some helper functions that construct our Timestream schema.
prepare_common_attributesbuilds our Timestream dimensionsprepare_recordis the top layer container that warps each measureprepare_measurebuilds each Timestream measure
Our table is formatted in Multi-measure records schema which allows for multiple measures per record. Below is the layout built by our helper functions and represents what an entry in our Timestream table looks like.
| Column | Type | Timestream attribute type |
|---|---|---|
| Contract_ID | varchar | DIMENSION |
| Market_Name | varchar | DIMENSION |
| Market_ID | varchar | DIMENSION |
| Contract_Name | varchar | DIMENSION |
| measure_name | varchar | MEASURE_NAME |
| BestNoPrice | double | MULTI |
| BestYesQuantity | bigint | MULTI |
| BestYesPrice | double | MULTI |
| BestNoQuantity | bigint | MULTI |
| LastTradePrice | double | MULTI |
| LastClosePrice | double | MULTI |
| time | timestamp | TIMESTAMP |
for contract in item['Contracts']:
contractsItemDict=defaultdict(def_value)
for field in MarketContractsItem.fields.keys():
contractsItemDict[field] = contract.get(field)
for field in ContractContractsItem.fields.keys():
contractsItemDict[field] = contract.get(field)
current_time = self._current_milli_time()
common_attributes = prepare_common_attributes(str(item['ID']),
str(item['Name']),
str(contractsItemDict['ID'] if contractsItemDict['ID'] else contractsItemDict['ContractId']),
str(contractsItemDict['Name'] if contractsItemDict['Name'] else contractsItemDict['ContractName']) )
record = prepare_record(current_time)
contractBestNoPrice=contractsItemDict['BestNoPrice'] if contractsItemDict['BestNoPrice'] else contractsItemDict['BestBuyNoCost']
if contractBestNoPrice is not None:
record['MeasureValues'].append(prepare_measure('BestNoPrice', contractBestNoPrice,'DOUBLE'))
contractBestBuyYesCost=contractsItemDict['BestYesPrice'] if contractsItemDict['BestYesPrice'] else contractsItemDict['BestBuyYesCost']
if contractBestBuyYesCost is not None:
record['MeasureValues'].append(prepare_measure('BestYesPrice', contractBestBuyYesCost,'DOUBLE'))
contractLastClosePrice=contractsItemDict['LastClosePrice']
if contractLastClosePrice is not None:
record['MeasureValues'].append(prepare_measure('LastClosePrice', contractLastClosePrice,'DOUBLE'))
contractLastTradePrice=contractsItemDict['LastTradePrice']
if contractLastTradePrice is not None:
record['MeasureValues'].append(prepare_measure('LastTradePrice', contractLastTradePrice,'DOUBLE'))
contractBestYesQuantity=contractsItemDict['BestYesQuantity']
if contractBestYesQuantity is not None:
record['MeasureValues'].append(prepare_measure('BestYesQuantity', contractBestYesQuantity,'BIGINT'))
contractBestNoQuantity=contractsItemDict['BestNoQuantity']
if contractBestNoQuantity is not None:
record['MeasureValues'].append(prepare_measure('BestNoQuantity', contractBestNoQuantity,'BIGINT'))
records=[record]
try:
_logging.info(f'records:{records}')
result = self.client.write_records(DatabaseName=settings.DATABASE_NAME,
TableName=settings.TABLE_NAME,
Records=records,
CommonAttributes=common_attributes)
Our pipeline class, MarketsPipeline, loops through the parsed contracts and writes records to our Timestream table.
Conclusion
In this section we're just performing an initual exploration into scraping predictit markets with our scrapy framework. We can test scrapy by running our spider on an EC2 instance in the same availability zones as our Timestream database by executing scrapy crawl markets. You should see several pages of scrapy logs printed to screen:
'Time': '2023-10-03T03:16:50.825516',
'URL': 'https://www.predictit.org/markets/detail/8077/What-will-be-the-Electoral-College-margin-in-the-2024-presidential-election'}
2023-10-03 03:16:57 [scrapy.core.engine] INFO: Closing spider (finished)
2023-10-03 03:16:57 [root] INFO: close Timestream...
2023-10-03 03:16:57 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 1358,
'downloader/request_count': 5,
'downloader/request_method_count/GET': 5,
'downloader/response_bytes': 26745,
'downloader/response_count': 5,
'downloader/response_status_count/200': 5,
'elapsed_time_seconds': 7.34493,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2023, 10, 3, 3, 16, 57, 608700),
'httpcompression/response_bytes': 116684,
'httpcompression/response_count': 5,
'item_scraped_count': 20,
'log_count/DEBUG': 3275,
'log_count/INFO': 411,
'log_count/WARNING': 1,
'memusage/max': 76316672,
'memusage/startup': 76316672,
'request_depth_max': 1,
'response_received_count': 5,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 4,
'scheduler/dequeued/memory': 4,
'scheduler/enqueued': 4,
'scheduler/enqueued/memory': 4,
'start_time': datetime.datetime(2023, 10, 3, 3, 16, 50, 263770)}
2023-10-03 03:16:57 [scrapy.core.engine] INFO: Spider closed (finished)
Querying our Timestream database shows data is being populated.
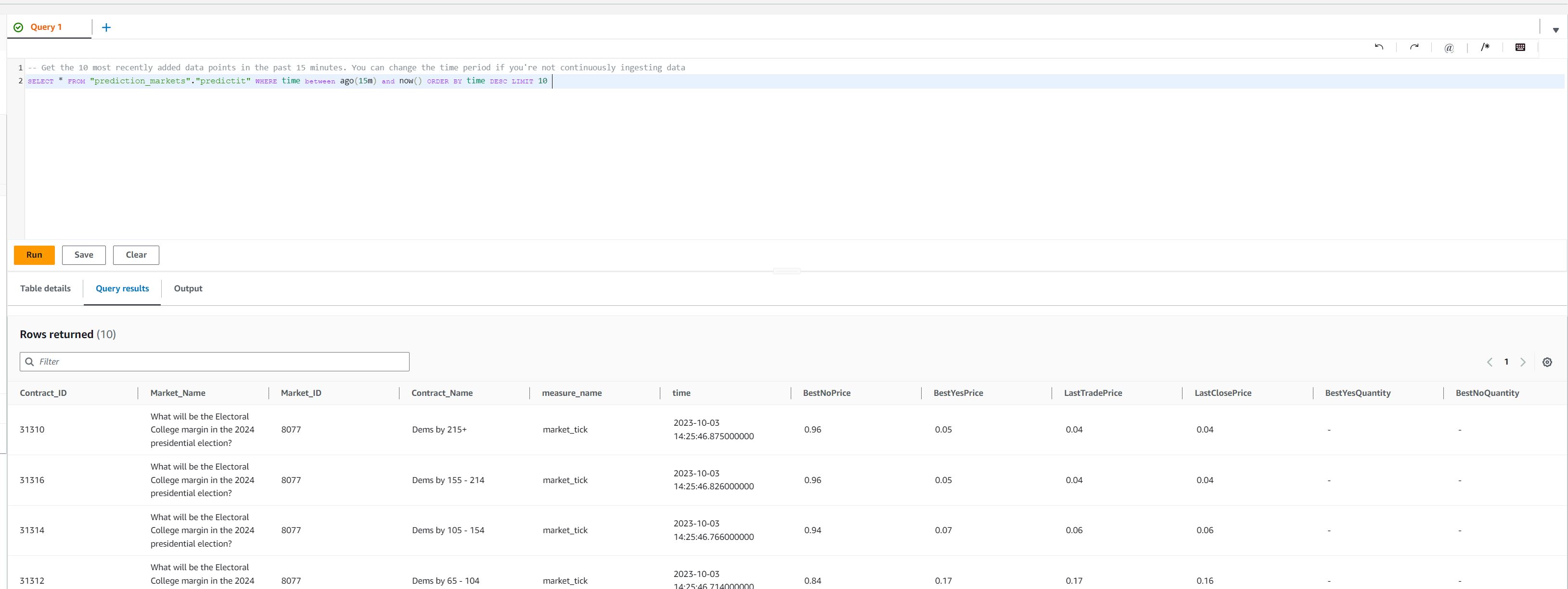
In the next section:
- Move our scrapy code into a lambda function
- Create an EventBridge Trigger to execute our lambda function on a schedule
- Generate true time series data for our Timestream database