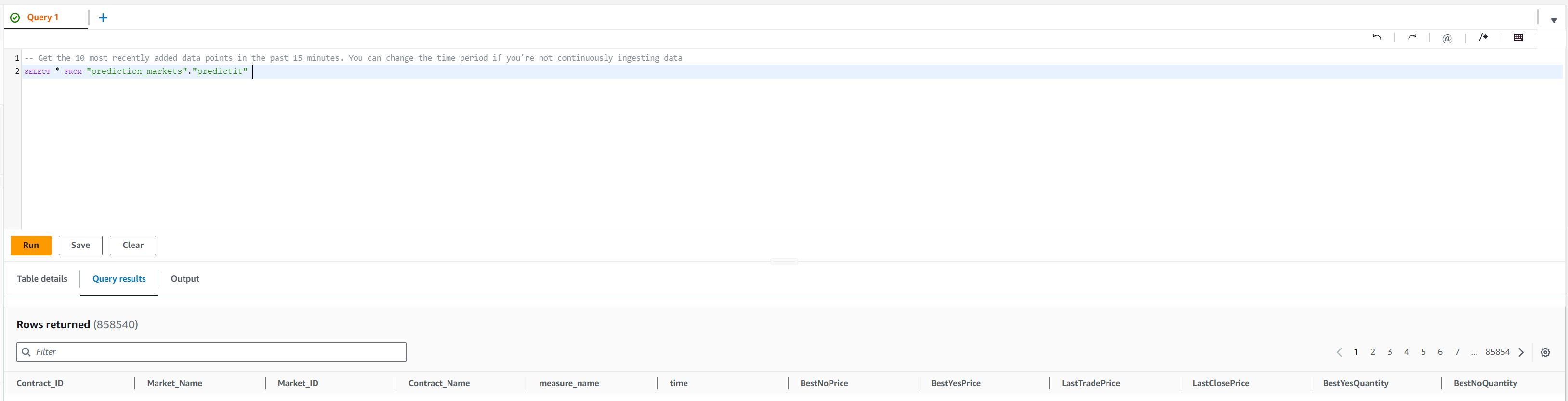
Populating Timestream With Scraped Predictit Market Ticks 2
Posted on Thu 26 October 2023 in Election Modeling
In the last section, we explored scraping predictit.com market data and storing results in a Timestream database. We implemented code to perform a single capture of market data. For our time-series dataset. A market capture accounts for a single point in the data dimension, but true time-series data must be captured through data and time dimensions.
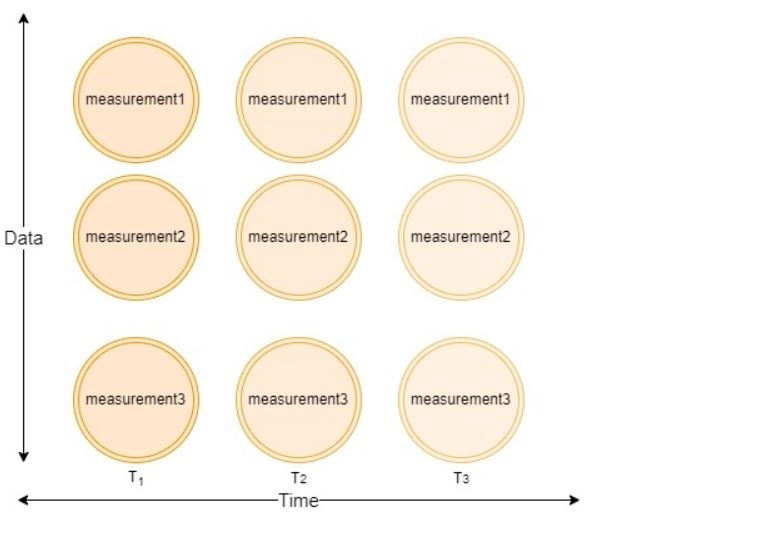
In this section, we build upon our single capture framework, and implement a schedular to capture market data at regular intervals. This will allow us to take full advantage the AWS timestream database to capture real-time time-series market data.
Architecture
our single capture implementation ran a scrapy spider on an EC2 server. In this section we're going to implement a fully serverless framework. To manage our serverless framework we're going to deploy our code using AWS Serverless Application Model (AWS SAM)
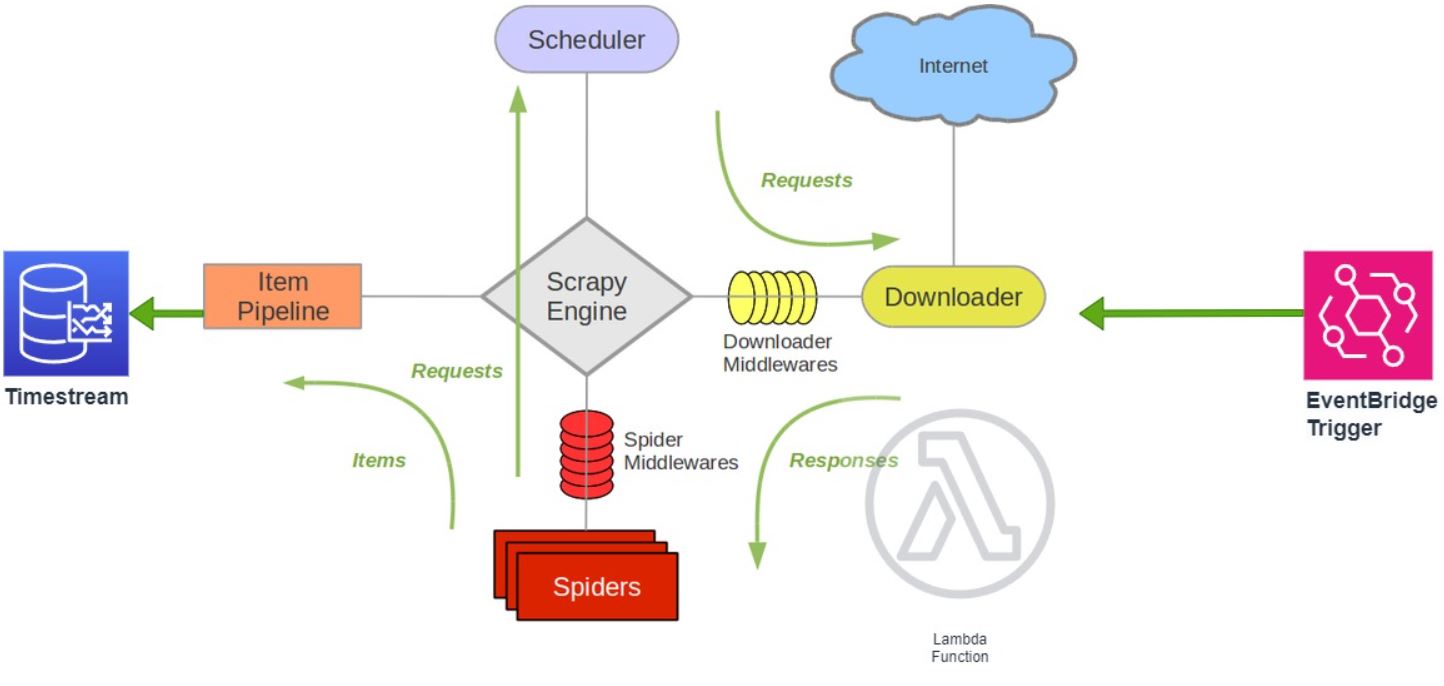
We expand the architecture from part 1 by:
- Moving our scrapy code into a lambda function
- Creating an EventBridge Trigger to execute our lambda function on a schedule
- Generate true time-series data for our Timestream database
Lambda Function
There are two parts needed to refactor our scrapy code set to run serverless on AWS lambda:
- Create lambda layer to contain required scrapy libraries.
- Move spider execution inline within lambda runtime
Lamda Layer
The lambda python runtime comes prepackaged with standard libraries. Any supplementary library dependencies need to be packaged in a zip file, and uploaded as a lambda layer. AWS Serverless Application Model (AWS SAM) is an open-source framework for quickly deploying serverless infrastructure, and provides an easy method of packaging dependencies for our lambda function.
The ASW site has good tutorials for prerequisite installation for AWS SAM:
Once the SAM CLI is installed, the full scraping stack can be built by calling sam build --use-container in the root of the project directory.
The build process is controlled by template.yaml, a YAML-formatted text file that describes the serverless infrastructure to be created, including the lambda layer:
scrapylayer:
Type: AWS::Serverless::LayerVersion
Properties:
ContentUri: scrapy_layer
CompatibleRuntimes:
- python3.11
Metadata:
BuildMethod: makefile
This builds our scrapy dependency based on our makefile and library requirements specified in requirements.txt located in the scrapy_layer directory:
build-scrapylayer:
mkdir -p "$(ARTIFACTS_DIR)/python"
python -m pip install -r requirements.txt -t "$(ARTIFACTS_DIR)/python"
Once built, we can deploy our serverless infrastructure to AWS with sam deploy --guided.

Lamda Handler
In part 1, we ran our spider with the following command line function scrapy crawl markets, but lambda runs python code, and in order to run our spider in a lambda funtion, we need to move the execution of our spider inline within the python runtime. To run a spider inline we use the CrawlerRunner class, a helper class that keeps track of, manages and runs crawlers inside an already setup reactor.
def run_spider(spider):
def f(conn):
try:
runner = crawler.CrawlerRunner(get_project_settings())
deferred = runner.crawl(spider)
deferred.addBoth(lambda _: reactor.stop())
reactor.run()
conn.send(None)
except Exception as e:
conn.send(e)
conn.close()
With repeated executions, the lambda python runtime get re-used. A problem arises when you attempt to start a twisted reactor more than once, and your code will throw ReactorNotRestartable error after the fist run. To work around this issue, we move our spider execution in a separate process.
parent_connections = []
parent_conn, child_conn = Pipe()
parent_connections.append(parent_conn)
#q = Queue()
p = Process(target=f, args=(child_conn,))
p.start()
p.join()
Finally, below is our lambda handler, it simpley runs the run_spider function from above
def lambda_handler(event, context):
configure_logging()
run_spider(MarketSpider)
EventBridge Trigger
Aside from moving our code to a lambda function, the other new addition to our predictit.com market scraping stack is an eventBridge Trigger. Our trigger will initiate the scraping routine within the lambda function to run at regular intervals to capture true, time-series data.
Like the lambda layer, the Eventbridge trigger is handled by the SAM template
Resources:
piscrapy:
Type: AWS::Serverless::Function
Properties:
CodeUri: MarketScrapy/
Handler: app.lambda_handler
Runtime: python3.11
Timeout: 180
Environment:
Variables:
DbName: !Ref TimestreamDatabaseName
TableName: !Ref TimestreamTableName
Layers:
- !Ref scrapylayer
Policies:
- AmazonTimestreamFullAccess
Events:
PredictitTrigger:
Type: AWS::Events::Rule
Properties:
EventPattern:
source:
- "aws.events"
PredictitTrigger:
Type: AWS::Events::Rule
Properties:
Description: "scrape every 2 minutes"
ScheduleExpression: "rate(2 minutes)"
State: "ENABLED"
Targets:
-
Arn: !GetAtt piscrapy.Arn
Id: "piscrapy"
PermissionForEventsToInvokeLambda:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref "piscrapy"
Action: "lambda:InvokeFunction"
Principal: "events.amazonaws.com"
SourceArn:
Fn::GetAtt:
- "PredictitTrigger"
- "Arn"
PredictitTrigger is the name of our EventBridge trigger, and is configured to run every 2 minutes.
Conclusion
In this section, we built upon our initial exploratory scrapy code, and built a fully managed scraping framework that scrapes predictit.com, and populates true, time-series data.
Querying the Timestream database, you can see it's being populated on a continues basis